

Tłumaczenie maszynowe jest jedną z dziedzin lingwistyki komputerowej, która bada wykorzystanie oprogramowania do tłumaczenia tekstu lub mowy z jednego języka na drugi.
Algorytmy tłumaczenia maszynowego zazwyczaj używają statystyk, korpusów i technik neuronowych do rozwiązywania problemów związanych z różnicami w typologii językowej, tłumaczeniami idiomów i wykrywaniem anomalii.
Obecne oprogramowanie do tłumaczenia maszynowego często pozwala na dostosowanie do potrzeb klienta ze względu na dziedzinę i specyfikę treści, poprawiając wydajność poprzez ograniczenie zakresu dopuszczalnych zastępstw. Technika ta jest szczególnie efektywna w dziedzinach, w których używany jest język formalny. Poprawę jakości wyjściowej można również osiągnąć poprzez interwencję człowieka.
Rodzaje silników tłumaczenia maszynowego
Tłumaczenie maszynowe oparte na regułach
Silnik tłumaczenia maszynowego opartego na regułach (Rule-based Machine Translation, RBMT) zawiera wbudowane informacje na temat lingwistyki języków źródłowych i docelowych, zasady morfologiczne i syntaktyczne oraz analizę semantyczną obu języków.
Jego działanie polega zatem na zastosowaniu wbudowanych reguł do zdania wejściowego i uzyskaniu w ten sposób docelowego tłumaczenia. Wadą tego rozwiązania jest to, że jakakolwiek wariacja zdania wejściowego czy zwykłe błędy w tekście źródłowym pociągają za sobą uzyskanie niezadowalających efektów. Rozbudowa takich silników i dostosowanie ich do nowych dziedzin jest również bardzo trudna ze względu na konieczność żmudnego wprowadzania zasad lingwistycznych do bazy danych silnika.
Statystyczne tłumaczenie maszynowe
Statystyczne tłumaczenie maszynowe próbuje generować tłumaczenia przy użyciu metod statystycznych opartych na dwujęzycznych korpusach tekstowych. Dysponując dobrej jakości korpusem można zatem osiągnąć dobre wyniki w tłumaczeniu podobnych tekstów. Niestety takie korpusy są nadal rzadkością w przypadku wielu par językowych.
Największą wadą silników statystycznych jest właśnie zależność od dużej ilości tekstów przetłumaczonych w danych parach językowych. Problematyczne są także te języki, które posiadają rozbudowaną morfologię oraz niemożność korygowania pojedynczych błędów.
Model hybrydowy
Silniki hybrydowe, jak można się domyślić, łączą zalety metody statystycznej i opartej na regułach. Podejście hybrydowe wykorzystuje zarówno reguły, jak i statystyki, z rozróżnieniem na dwa sposoby:
- reguły korygowane przez statystykę, kiedy to tłumaczenie jest “wykonywane” z wykorzystaniem silnika opartego na regułach, a następnie wykorzystywane są algorytmy statystyczne do weryfikacji i korekty danych wyjściowych,
- statystyki oparte na regułach, gdzie to reguły są wykorzystywane do wstępnego przetworzenia danych w celu lepszego ukierunkowania silnika statystycznego i normalizacji tekstu.
To podejście oferuje oczywiście dużo więcej kontroli nad procesem tłumaczenia i owocuje znacznie wyższą jakością tekstu docelowego, niestety jednak technologia ta jest bardzo trudna w implementacji i utrzymaniu.
Neuronowe tłumaczenie maszynowe
Neuronowe tłumaczenie maszynowe (NMT) to podejście do tłumaczenia maszynowego, które wykorzystuje sztuczną sieć neuronową do przewidywania prawdopodobieństwa sekwencji słów, zazwyczaj modelując całe zdania w jednym zintegrowanym modelu.
Modele silników neuronowych wykorzystują najczęściej tzw. głębokie uczenie - jedną z metod uczenia maszynowego (dziedzinę sztucznej inteligencji), która wcześniej była używana np. do rozpoznawania obrazów.
Większość nowoczesnych modeli głębokiego uczenia opiera się na sztucznych sieciach neuronowych, których każdy poziom uczy się przekształcać swoje dane wejściowe w nieco bardziej abstrakcyjną reprezentację. Słowo "głębokie" odnosi się właśnie do liczby warstw, przez które dane są przekształcane (tym też różni się od uczenia płytkiego).
Głębokie modele są w stanie zwrócić efekty o znacznie wyższej jakości niż modele płytkie, a zatem dodatkowe warstwy pomagają w efektywnym poznawaniu cech. Algorytmy głębokiego uczenia maszynowego mogą być również stosowane do zadań edukacyjnych bez nadzoru, czyli takich, gdzie nie mamy danych wyjściowych lub są one niepełne, co prowadzi do odkrywania nowych i nieznanych regularności w próbce danych. Jest to ważna korzyść, ponieważ danych nieoznakowanych jest znacznie więcej niż danych oznakowanych.
Modelowanie sekwencji wyrazów było na początku zazwyczaj wykonywane przy użyciu rekurencyjnych sieci neuronowych (Recurrent Neural Network, RNN). Dwukierunkowa rekurencyjna sieć neuronowa, znana jako koder, była używana do kodowania zdania źródłowego dla drugiej sieci - dekodera - która przewidywała słowa w języku docelowym.
Konwolucyjne sieci neuronowe (Convolutional Neural Networks, CNN) dawały lepsze efekty w przypadku długich sekwencji tekstu, ale początkowo nie były szeroko wykorzystywane aż do roku 2017 dzięki zastosowaniu tzw. podejść opartych na uwadze (tzw. Attention-based Neural Machine Translation).
Wraz z pojawieniem się neuronowych silników tłumaczenia maszynowego, pojawiła się także nowa wersja hybrydowego tłumaczenia maszynowego, łącząca w sobie zalety reguł, statystycznego i neuronowego tłumaczenia maszynowego. Minusem jest oczywiście duża złożoność, która sprawia, że podejście to jest odpowiednie tylko dla konkretnych przypadków użycia.
Producenci tłumaczenia maszynowego
Istnieje bardzo duża liczba producentów silników tłumaczenia maszynowego, ponieważ możemy rozróżnić wiele odmian tych silników. W tym opracowaniu zajmujemy się wyłącznie silnikami gotowymi do użytku, nie personalizowanymi i nie wdrażanymi na zamówienie.
Główni dostawcy tłumaczeń maszynowych to (w kolejności alfabetycznej):
- Alibaba Cloud,
- Amazon (AWS),
- Baidu,
- DeepL,
- Google Cloud,
- GTCom/YeeCloud,
- IBM Watson,
- Microsoft Translator,
- ModernMT,
- Naver/Papago,
- NiuTrans,
- Promt,
- SDL (SMT),
- Sogou,
- Systran PNMT,
- Tencent Cloud,
- Yandex,
- Youdao Cloud
- oraz wiele innych.
Który silnik tłumaczenia maszynowego jest najlepszy?
Odpowiedź nie jest oczywista i jednakowa dla wszystkich, ale istnieje wiele danych, na których można oprzeć swoje rozważania. Decydując o wyborze silnika tłumaczenia maszynowego, powinniśmy odpowiedzieć sobie na najważniejsze pytania:
- Jakie pary językowe nas interesują?
- Jaka jakość będzie nas zadowalać?
- Ile możemy za to wszystko zapłacić?
Firma inten.to, oferująca dostęp do wielu silników tłumaczenia maszynowego w jednym API programistycznym, na bieżąco bada jakość silników tłumaczenia maszynowego i co jakiś czas publikuje raporty - ostatni w czerwcu 2019. Jakość tłumaczenia jest mierzona poprzez obliczenie współczynnika LEPOR, który uwzględnia odległość tłumaczenia docelowego od tekstu źródłowego, czyli uogólniając - ile poprawek musiałby wykonać postedytor przed oddaniem tekstu do klienta. Te silniki, które uzyskują współczynnik LEPOR mniejszy niż 0,5% są określane jako najlepsze, te poniżej 5% jako dobre, a najtańsze z dobrych są określane jako optymalne. Niestety firma w swoich badaniach nie uwzględnia języka polskiego.
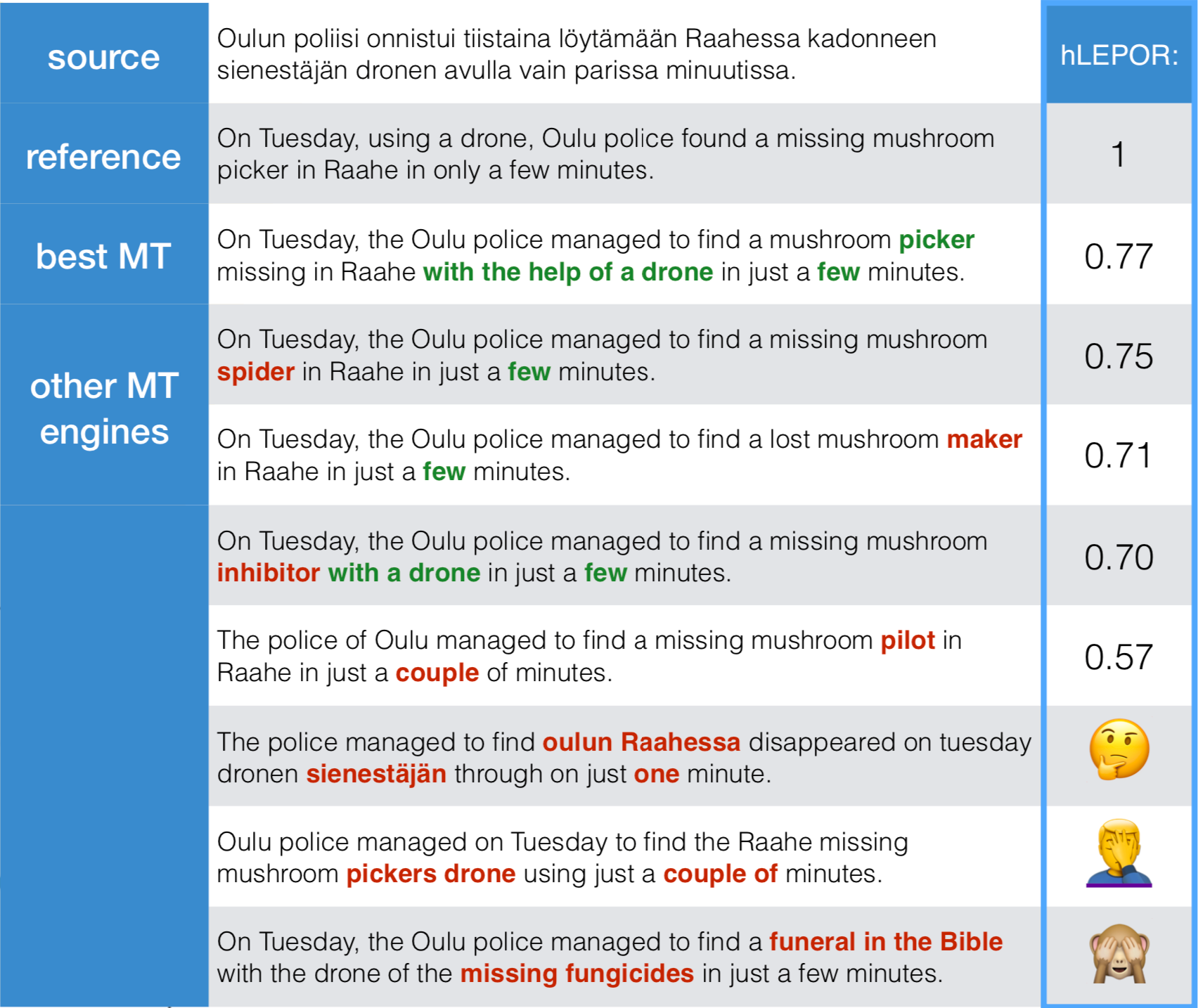
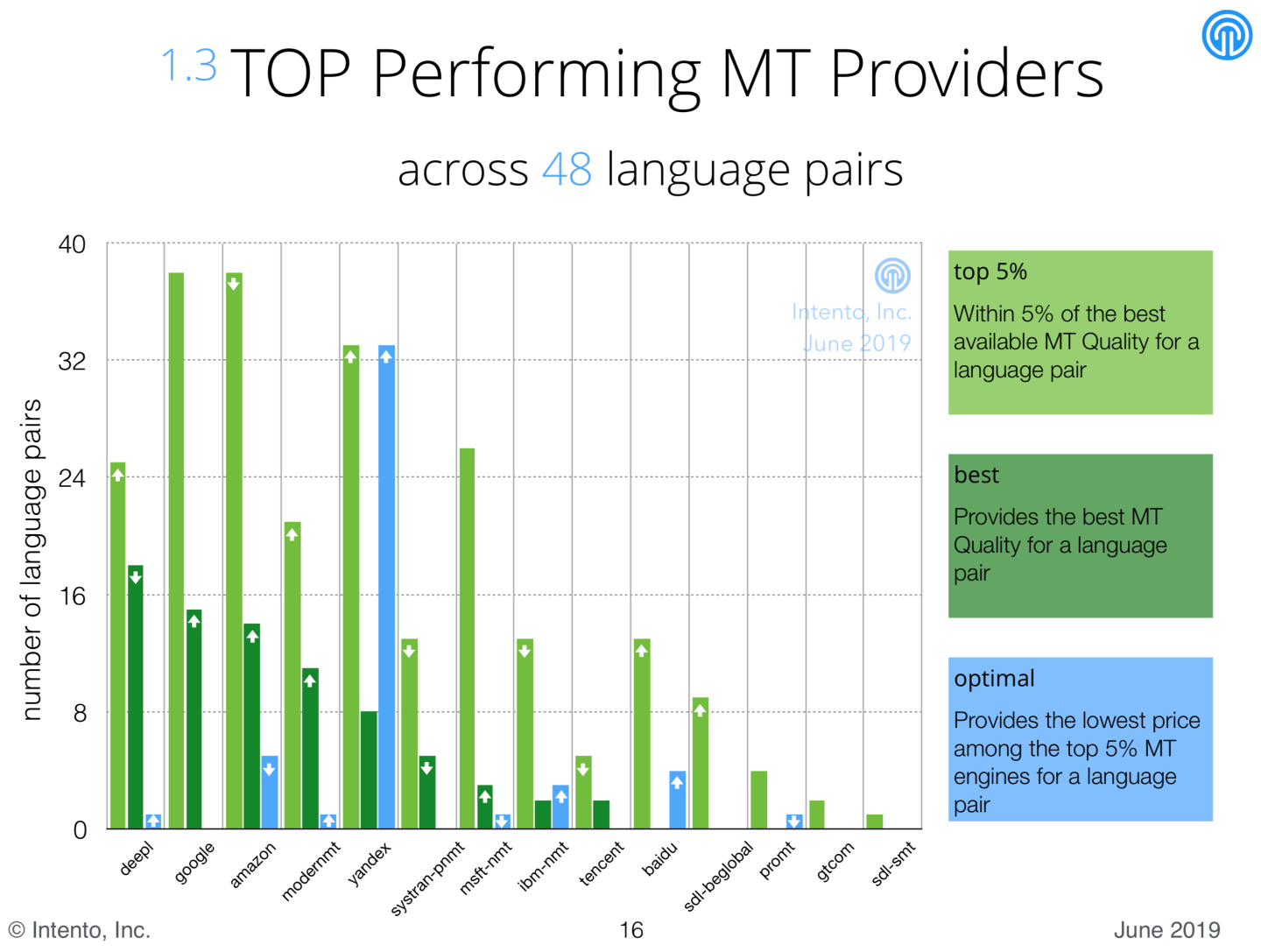
“Najczęściej najlepszy” silnik tłumaczenia maszynowego
Według wyników uzyskanych we wszystkich parach językowych, najczęściej w grupie najlepszych silników znajdował się DeepL, zaraz za nim Google Cloud, Amazon i ModernMT. Natomiast w kategorii “jakość a cena” bije na głowę konkurentów Yandex.
Pokrycie par językowych
Kolejnym istotnym kryterium wyboru jest pokrycie par językowych przez silniki tłumaczenia maszynowego. Poniższe zestawienie prezentuje obrazowo liczbę obsługiwanych języków: króluje NiuTrans, za nim plasuje się Google Cloud, Yandex oraz Microsoft i Sogou.

Dalszy rozwój tłumaczeń maszynowych
We wspomnianym raporcie, możemy również przeczytać, że konsekwentnie, z roku na rok, rośnie liczba dostępnych silników tłumaczenia maszynowego, a te, które już istnieją, uzyskują coraz lepsze wyniki w testach jakości. Rośnie także, szybciej niż w latach ubiegłych, liczba obsługiwanych języków.
Nie bez znaczenia pozostaje także fakt, że wysoka jakość tłumaczeń nie wiąże się z rosnącymi kosztami, a wręcz przeciwnie - ze względu na rosnącą liczbę dostawców, ceny dostępu do silników tłumaczeń maszynowych stają się coraz niższe i rozpoczynają się od 2,99 $ za milion znaków.



Komentarze